Tagged with
Kubernetes

24 June 2026 06:30 PM
Deploy Qwen2.5-1.5B-Instruct on a Kubernetes GPU node with vLLM, expose it as an OpenAI-compatible API, and verify it with a real curl request.

12 June 2026 12:30 PM
A practical teardown of OpenAI's public Kubernetes scaling posts: whole-node pods, direct pod IP networking, MPI-style jobs, checkpointing, API server pressure, EndpointSlices, metrics, health checks, and what smaller LLM platform teams should copy without copying OpenAI's scale.

4 June 2026 05:29 PM
Before Kubernetes can schedule LLM workloads onto GPUs, the node has to expose the right device resources, labels, runtime support, metrics, sharing mode, and operational boundaries. This article explains the GPU node setup behind serious LLM deployments on Kubernetes.

28 May 2026 09:00 AM
A practical look at why giant LLMs do not simply run inside one pod: weight memory math, FP16 and BF16 cost, tensor parallelism, pipeline parallelism, expert parallelism, MoE active parameters, and what Kubernetes is actually scheduling.
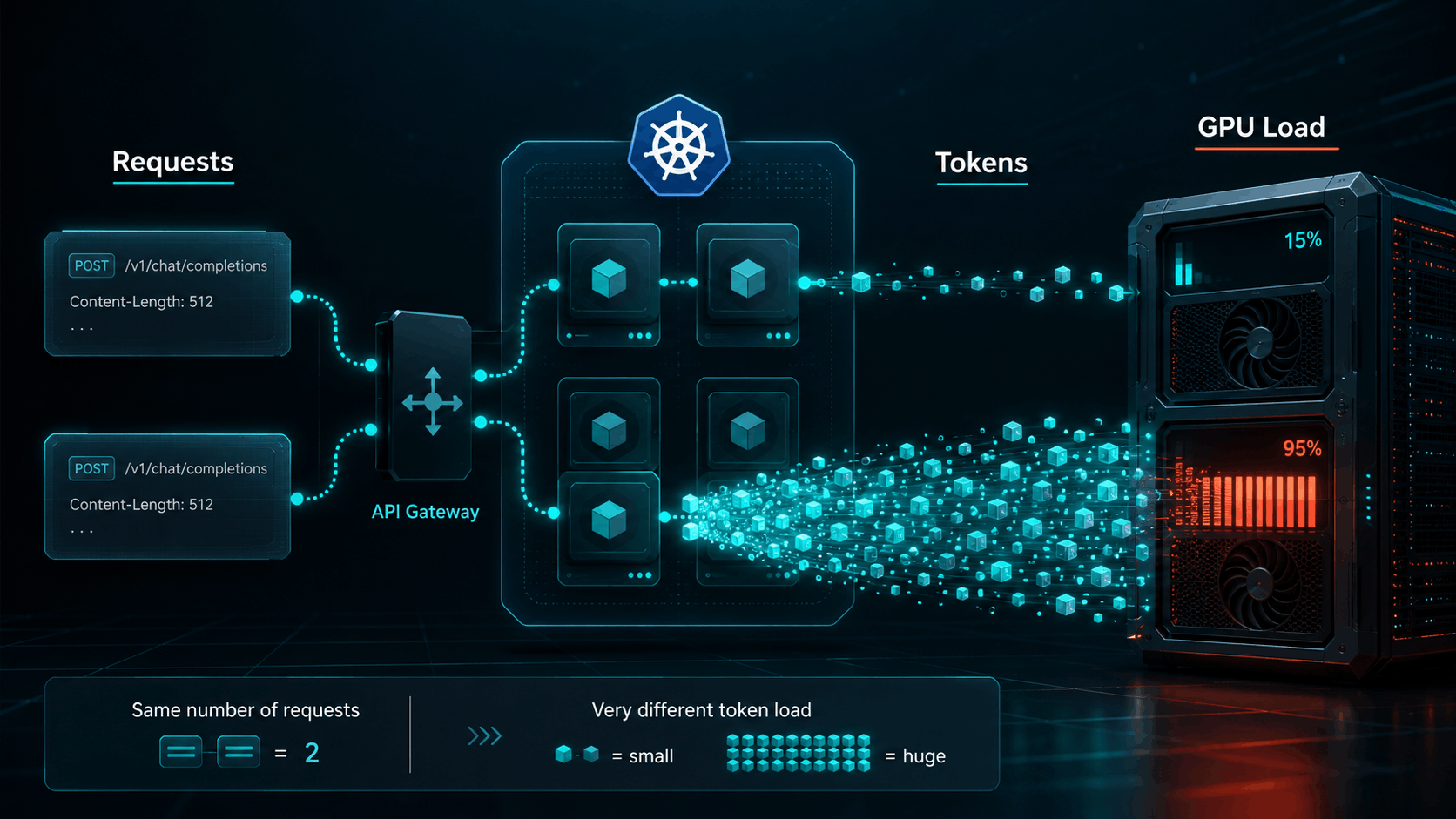
21 May 2026 09:00 AM
Request count works for normal web apps, but it breaks down when you serve LLMs on Kubernetes. Prompt length, output length, RAG context, KV cache pressure, GPU capacity, latency, and observability are all driven by tokens, not requests.
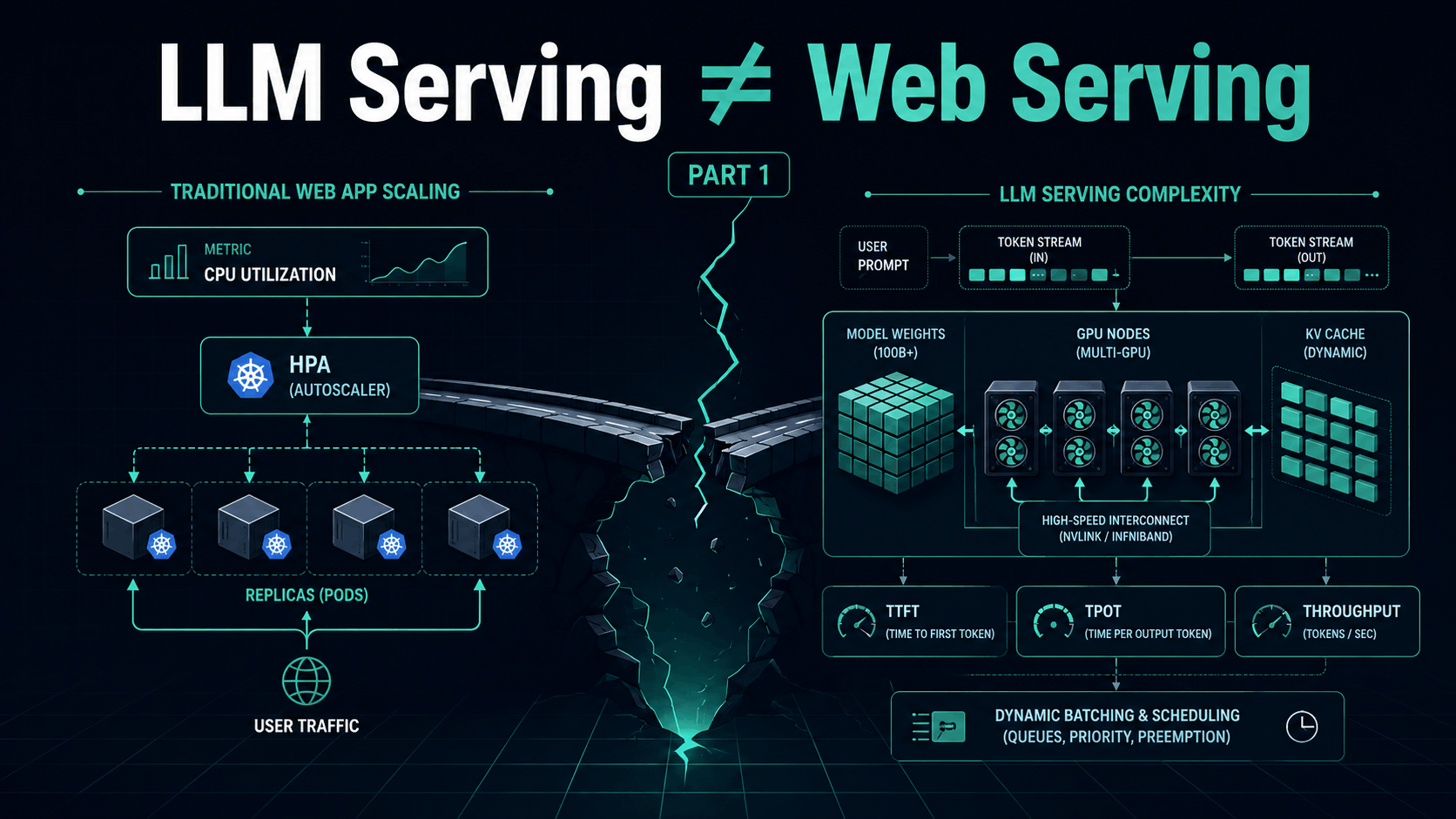
14 May 2026 09:00 AM
A practical introduction to why LLM serving breaks the usual web-app scaling playbook: requests become token streams, latency splits into TTFT and TPOT, replicas may span GPUs or nodes, memory becomes KV cache, and autoscaling needs workload-aware signals instead of CPU alone.